SPSS appendix til slides
1 Datasæt
Alle datasets er tilgængelige fra http://publicifsv.sund.ku.dk/~sr/BasicStatistics/datasets/.
Hvordan du importerer data til SPSS fremgår af SPSS intro om data import.
Filerne ligger i forskellige tekstformater (.txt eller csv) og også SPSS (.sav)
1.1 Vitamin D
Data er beskrevet i detaljer i Andersen et al. (2005) ‘Teenage girls and elderly women living in northern Europe have low winter vitamin D status’, European Journal of Clinical Nutrition.
Variables:
- country (1=DK, 2=FI, 4=EI, 6=PO)
- vitd (nmol/L, serum Vitamin D level)
- age (years)
- bmi \(({\rm kilo/m}^2)\)
- sunexp (1=Avoid sun, 2=Sometimes in sun, 3=Prefer sun)
- vitdintake (Vitamin D intake, the amount of vitamin D contained in the consumed food)
Data ligger tilgængeligt i filen vitamin .

Hvis problemer med at indlæse csv-filen i SPSS - virker instruktionerne i SPSS intro om data import ikke? Det kan måske have noget medd Dansk/Engelsk SPSS at gøre. En løsning kan være: Åbn csv-filen i Excel og gem som en Excel fil. Ser filen mærkelig ud (det hele er klumpet sammen i en søjle), skal du først bede Excel organisere data i søjler: Når csv-filen er åbnet benyt menu Data -> Text to Columns -> Delimited -> vælge Comma som delimiter og tryk Finish. Så skulle data gerne stå i søjler, gem som Excel, og prøv så at læse data ind i SPSS via menuen File / Import Data / Excel. Ellers kan du benytte .sav-filen som burde glide ind uden problemer….
Når du har indlæst data i SPSS, kan du lægge labels på de kategoriske variable(country og sunexp), så det er lettere at huske kodningen: Se hvordan i SPSS intro adjusting the properties of the variables). I Variable View skal data se sådan ud (tryk på knappen med den røde cirkel for at få SPSS til at vise value labels i stedet for selve værdierne):
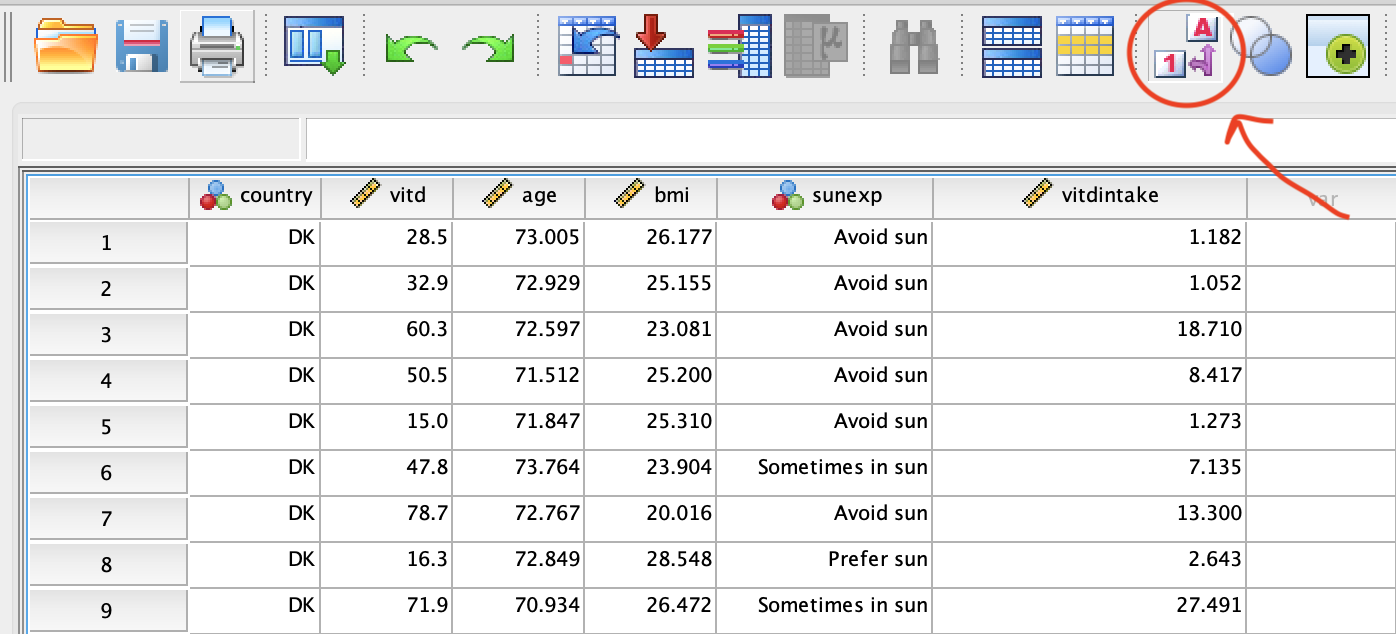
Vi kommer også til at arbejde på et subdatasæt bestående kun af de irske kvinder. Dette gøres via Data/Select cases (se evt kapitel 14.1)
1.2 Immunoglobulin
Data ligger i filer med navn imm (.csv eller .sav).
Her er kun én variabel med navn img:

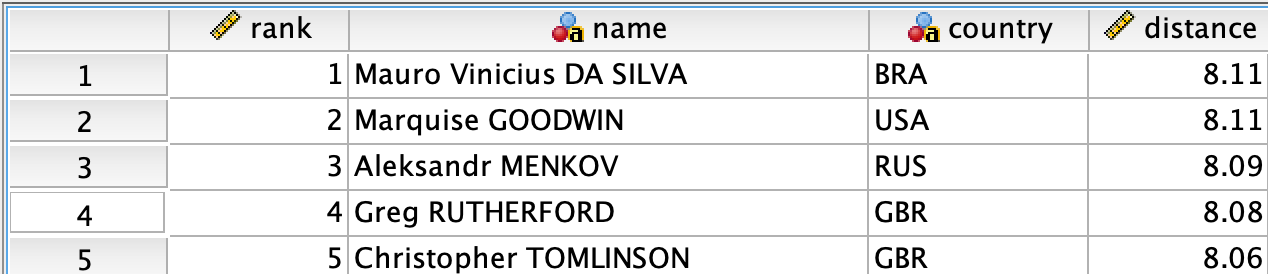
1.3 Længdespring
Længespring mænd, kvalifikation OL 2012, bedste spring af 3. Datasæt med navn longjump. Vi skal kun bruge variablen distance, som angiver længden:
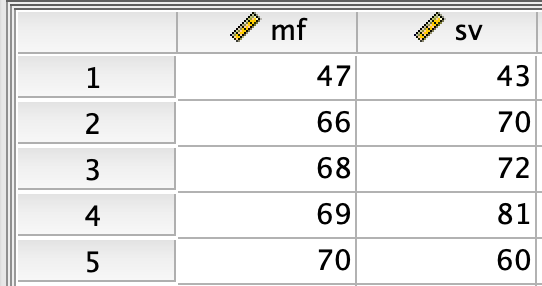
1.4 Slagvolumen, parrede observationer
Data finder du i filen mf_sv (den findes både som .txt og .sav (SPSS). Slagvolumen er bestemt ved to forskellige metoder for hver patient:
mf: Doppler ekkokardiografisv: Cross-sectional ekkokardiografi
Data skal også benyttes i såkaldt langt format i forbindelse med spaghettiplots (hvor mf og sv-målingerne er stablet ovenpå hinanden i en variabel med navn vol og vi har tilføjet en metode-variabel, som angiver om målingen er taget med mf eller sv):

1.5 Vietnam veteraner
Data er beskrevet i detaljer i Carroll et al.: Low cognitive ability in early adulthood is associated with reduced lung function in middle age: the Vietnam Experience Study, Thorax (2011)
Vi har et tilfældigt udsnit af data på 87 af de 4526 veteraner, som var en del US army mellem 1965 og 1971.
Datasættet (filer med navn viet) indeholder følgende variable:
smoke01: 0 = Ikke- eller ex-ryger, 1 = Ryger.iq: IQ målt ved start ansættelseFEV1: (L, Forced Expiratory Volume in one second) målt i 1986
1.6 VCF og blodsukker
Data (fil med navn vcf (.txt eller .sav)) indeholder to variable målt på 23 diabetikere:
blodsukkervcfsammentrækningsevne for venstre hjertekammer (velocity of circumferential shortening)
1.7 Refe og test
To forskellige metoder til bestemmelse af glucosekoncentration. Ref: R.G. Miller et.al. (eds): Biostatistics Casebook. Wiley, 1980.
Data (fil med navn refe_test (.txt eller .sav)) indeholder to variable målt på 46 individer
refe, farvetest der kan ’forurenes’ af urinsyretest, enzymatisk test, mere specifikt for glucose.
1.8 Lille SundBy
Data med navn sundby_lille (.txt eller .sav).
er et subdatasæt på 100 tilfældige individer fra SundBy-materialet. Her er tre variable
genderkodet “male” og “female”vaegti kghoejdei meter
1.9 AMH og P-piller
Data (fil med navn ppills, .txt eller .sav) indeholder to variable målt på 732 danske kvinder:
amhppiller, P-pille bruger 0/1 (nej/ja)
1.10 Fødselsvægt (Secher)
Data benyttes i uge 6, multipel regression.
Data (fil med navn secher, .txt eller .sav) indeholder 4 variable målt ved 107 ultralydsscanninger:
vaegtfødselsvægtbpdhoveddiameteradmaveomfangetnrobservationsnummeret
1.11 Fedme
Data benyttes i uge 6, multipel regression.
Datasættet (filer med navn fedme) indeholder følgende målinger på 197 børn:
vaegtvægt i 1-års alderhoejdehøjdde i 1-års alderfedmei skolealderen - skal normeres således at vi regner påfedmescore=fedme/0.2859382(0.2859382 er SD affedme-variablen)
1.12 Lungefunktion og cystisk fibrose
Data benyttes i uge 6, multipel regression.
Datasættet (filer med navn pemax) indeholder målinger fra
et studie af 25 patienter, hvor outcome er pemax (et udtryk
for lungefunktion) og 9 kovariater: age, sex, height, weight, bmp, fev1, rv, frc og tlc. Se evt. O’Neill et. al. (Am Rev Respir Dis, 1983).
1.13 Biokemisk iltforbrug (BOC)
Datafil med navn boc, benyttes i uge 7 (den generelle lineære model).
Iltsvind i lukkede flasker (Biochemical Oxygen Consumption, BOC), som funktion af antal dage. Datasættet indeholder 24 målinger og to variable:
days, antal dageboc, iltsvind (BOC)
1.14 Serum IGF
Datafil med navn juul2, benyttes i uge 7 (den generelle lineære model). Datasættet indeholder følgende variable målt på 1340 individer
agealder i årheighthøjde i cmmenarchesexnrkøn (1=male, 2=female)sigf1Serum IGF-1tanner, Tanner’s pubertetsklassifikation (1–5)testvolweightvægt i kg
1.15 RES-systemet i leveren
Datafil med navn kw benyttes i uge 7, den generelle lineære model. Eksempel på ikke-lineær sammenhæng.
Indeholder to variable målt på 26 individer:
koncentration, koncentration af radioaktiv tracertid, tid for målingen afkoncentrationefter bolus injektion ved tid 0
1.16 Blodtryk og fedme
Datafil med navn bp benyttes i uge 7, den generelle lineære model.
Datasættet indeholder 3 variable målt på 102 individer
sexnrkøn (1=male, 2=female)obesefedmegrad, vægt/idealvægtbpsystolisk blodtryk
1.17 Prostatakræft
Datafil med navn prostate benyttes i uge 8, logistisk regression.
Datasættet indeholder 6 variable målt på 380 mænd med prostatakræft. Formålet med undersøgelsen er at bestemme hvordan risikoen for at tumor er trængt igennem prostatakapslen afhænger af forklarende variable og hvorvidt disse variable kan benyttes til at prædiktere gennemtrængning. Variablene er
gennemtraengning01tumor har penetreret kapslen (0=nej, 1=ja)involveringkapsel involvering ved rektal eksploration (0=ej involvering, 1=involvering)knudeknudes placering på lap (“ingen”,“venstre”,“hoejre”,“begge”)psaProstataspecifikt Antigen i Plasma (PSA, ng/ml)alder65Under / over 65 år (“Under”/“Over”)gleasonGleason score, 0-10.
Når jeg indlæser filen prostate.txt, er Gleason registreret som Nominal, men vi skal bruge den som Scale. Det ændres i Variable View.
Data er lånt fra Hosmer & Lemeshow: Applied Logistic Regression, 2nd ed.
1.18 Lungecancer
Datafiler med navn veteran benyttes i uge 9 om overlevelsesanalyse.
Datasættet indeholder 9 variable observeret for 137 mænd. Af de 9 variable kommer vi til at benytte følgende 5:
timeTid fra randomisering til død/censureringstatusAngiver omtimeer observation af død eller censurering (1 = død, 0 = censurering)treatBehandling (0 = standardbehandling, 1 = ny behandling)celltypeType af lungecancer (4 forskellige typer)karnoKvantitativ Karnofsky score